The recent surge in large language models (LLMs) has opened up vast possibilities for various AI services, from sophisticated chatbots to advanced coding assistants. However, a key capability required for these applications—handling exceptionally long input texts, often referred to as "long context" or "long text processing"—remains a significant hurdle.
Whether dealing with a massive code repository, a history of chat interactions, or token-heavy multi-modal inputs (like high-resolution images or videos), the ability to process long inputs is becoming increasingly critical.
This post dives into REFORM (Recurrent Encoding with RecoMputation), a groundbreaking new method developed by Woomin Song and his colleagues at KAIST, designed to overcome the efficiency and performance issues associated with long context inference.
The Bottleneck: Why Long Context is Hard
The core challenge lies primarily in the architecture of the Transformer model and its attention mechanism.
- The N2 Problem: Transformer attention requires every token to interact with every other token. If the number of tokens is N, the computational cost scales quadratically (N2). As context length increases, the required computation rapidly becomes prohibitive.
- Memory Overload: Storing the Key-Value (KV) cache, essential for efficient decoding in Transformers, also increases proportionally with the context length, putting significant strain on GPU memory.
- Context Limitations: LLMs trained on a specific context limit (e.g., 2K tokens) often experience a dramatic performance drop if that limit is slightly exceeded during inference.
Existing Solutions: A Trade-off
To address these limitations, existing inference-time algorithms generally fall into two camps:
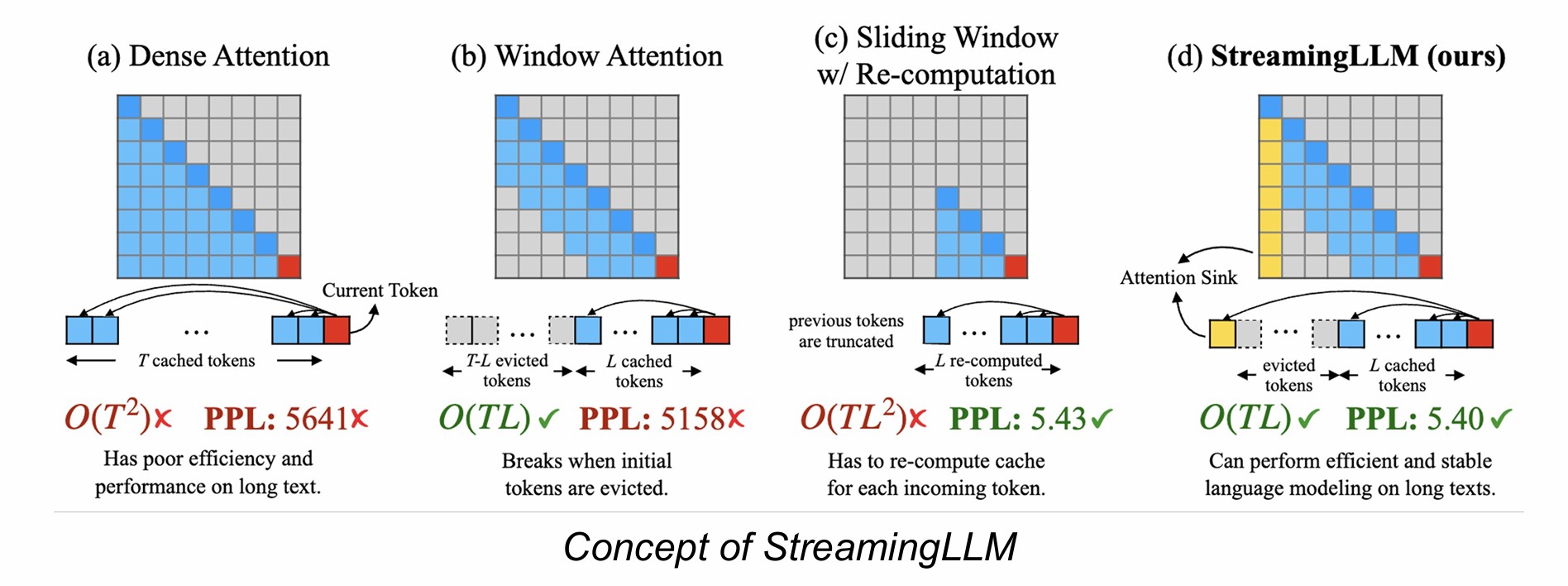
- Recurrent Compression Approaches (e.g., StreamingLLM, H2O): These methods divide the long input into chunks and process them sequentially. They often compress or discard older, less critical KV cache entries to manage memory. While efficient, this approach lacks random access because essential information might be discarded during compression.
- Random Access Approaches (e.g., Retrieval-based methods like Infini-attention): These aim to allow access to any part of the context. They typically store the entire KV cache (often offloading it to CPU memory) and retrieve necessary pieces. While offering random access, this approach demands vast memory resources and can introduce latency due to memory offloading.
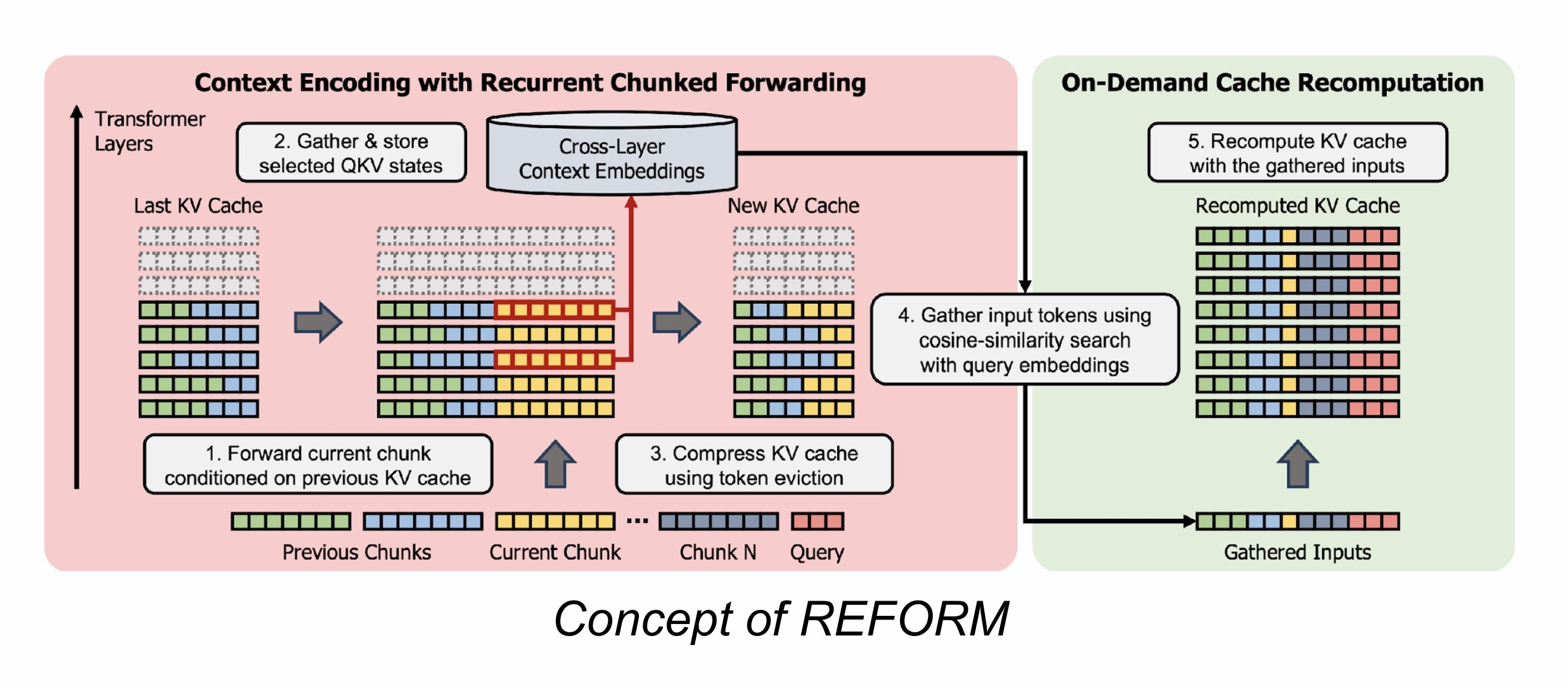
Introducing REFORM: Efficiency Meets Retrieval
The REFORM method seeks to combine the efficiency of recurrent compression with the crucial ability of random access. The technique is built on three core stages: Compress, Gather, and Recompute.
1. Compress Stage: Encoding and Early Exit
In the initial stage, the long input is broken down into manageable chunks.
- The model processes the first chunk using a standard forward pass for a few initial layers.
- A key insight is that not all layers are necessary for good retrieval performance. REFORM identifies which attention QKB (Query, Key, and Value) states from which specific layers and heads are most effective for future retrieval.
- The system then employs an Early Exit strategy, skipping the computation of unnecessary upper layers during the forward pass to save resources and boost efficiency.
- These selected, important QKB embeddings are extracted and stored in an embedding storage.
- For subsequent chunks, the process repeats, but the KV cache is conditioned on the compressed KV cache of the preceding chunk (using methods like H2O compression). This conditioning helps the model maintain contextual understanding during sequential encoding, mitigating the fragmentation problem often seen in simple chunking methods like RAG.
2. Gather Stage: Searching for the Needle
When a final query is presented, the Gather stage identifies which parts of the previously encoded context are essential for generating the correct answer.
- REFORM searches the stored context embeddings using Cosine Similarity to compare them against the query embedding.
- Crucially, the authors observed that leveraging the Cosine Similarity of the hidden states or QKB embeddings is often more effective for direct retrieval than relying on attention scores alone.
- To ensure contextual coherence—and prevent a key piece of information from being isolated—REFORM applies a neighborhood pooling strategy (max pooling of scores with surrounding tokens, tested at about 128 tokens). This ensures that if a highly relevant token is found, its immediate surrounding context is also prioritized for retrieval.
- This search results in a set of tokens deemed most critical for answering the query.
3. Recompute Stage: RecoMputation
The final stage takes the identified tokens and uses them to construct the final output.
- The selected, important tokens are gathered and re-fed through the model to recompute their precise KV cache information.
- This newly computed KV cache, containing the most relevant information from the long context, is then used for standard decoding and final answer generation.
- The overhead associated with this recomputation step is minimal (e.g., measured at only 0.4 seconds).
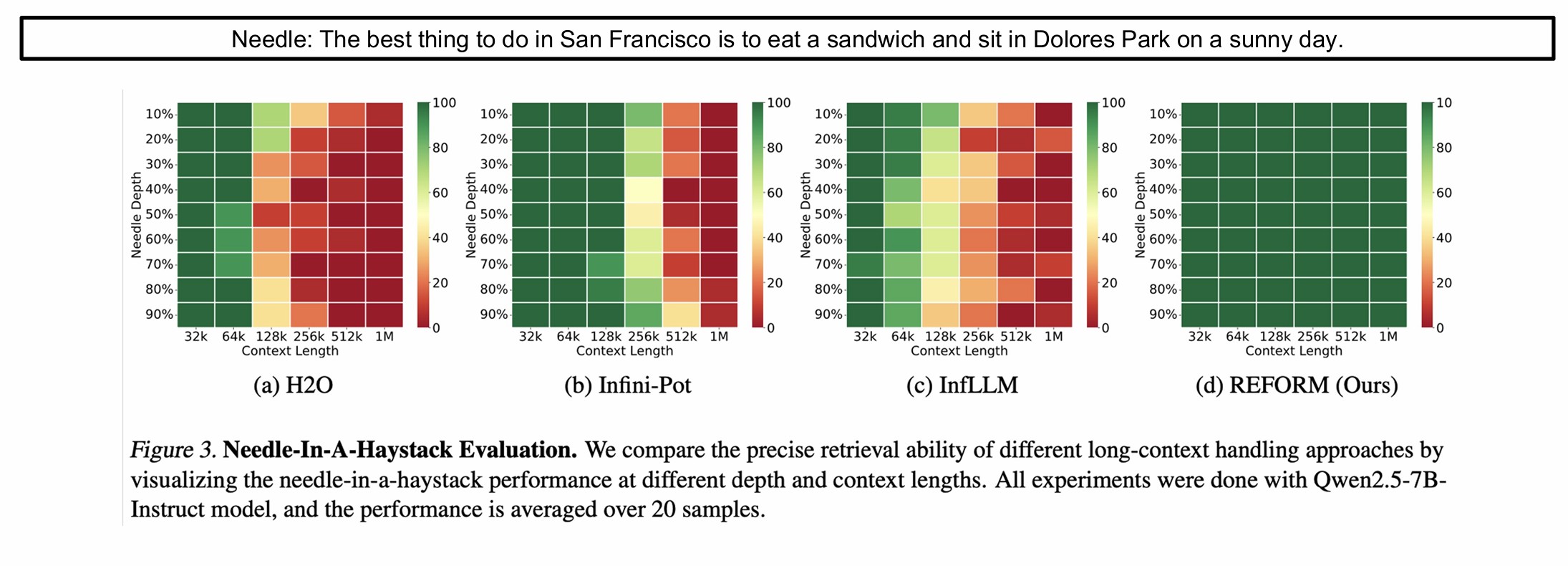
Exceptional Results Across the Board
REFORM was rigorously evaluated across synthetic and realistic benchmarks, consistently demonstrating superior performance.
On foundational benchmarks like Needle in a Haystack (where a key fact is hidden randomly within a very long document), REFORM showed dramatic advantages:
- Performance on Long Contexts: Unlike recurrent compression approaches (like H2O) where accuracy sharply drops as context length increases due to information loss, REFORM maintains high accuracy.
- 1 Million Token Context: On challenging synthetic benchmarks like Ruler and Babylon, REFORM achieved impressive results (e.g., over 75% accuracy) on 1 million token inputs, compared to only 4% to 23% for competitive baseline methods. This confirms its robust ability to effectively retrieve information regardless of where it lies.
Efficiency Gains
One of REFORM's strongest features is its efficiency advantage. It showed both lower inference time and lower memory usage compared to baseline methods. This efficiency is directly attributable to the Early Exit strategy used in the Compress stage, which reduces the computational load needed to create the embeddings.
Architecting Beyond RAG
REFORM offers distinct advantages over typical Retrieval-Augmented Generation (RAG) systems:
- Context Preservation: While RAG often suffers from fragmentation (losing context at chunk boundaries), REFORM’s recurrent encoding, conditioned on the previous chunk's KV cache, ensures better contextual understanding during the initial embedding process.
- Internal Solution: RAG relies on external retrieval models (like BM25 or dedicated neural retrievers), which must be separately trained and maintained for specific domains (e.g., code, medical). REFORM, however, is an architecture-level solution. It functions solely using the base LLM, meaning it naturally handles any domain that the underlying LM is trained on, without the need for an external retrieval component.
Performance comparison of REFORM vs. baselines
Conclusion
REFORM successfully bridges the gap between efficient sequential processing and crucial random access capabilities. By selectively storing key QKB states and employing targeted retrieval via Cosine Similarity and recomputation, it proves that long-context AI can be both powerful and resource-efficient. It’s an approach that looks set to become a foundational component in the next generation of scalable and intelligent LLM applications.