Overview
Large Language Models are revolutionary, but running them for real-world applications is often slow and inefficient. This is due to a massive, hidden challenge: the underutilization of expensive GPU memory. In many setups, over half of a GPU's valuable VRAM can go unused. This doesn't just waste memory; it severely limits throughput—the number of requests you can serve simultaneously.
This presentation provides a 10,000-foot view of the vLLM system architecture, one of the first open-source LLM inference tools, and explains how it addresses critical challenges in the LLM inference space through novel engineering approaches.
The Core Problem: Memory Management
Before vLLM, more than half of the available GPU VRAM was often unutilized, which not only wasted memory but also negatively impacted throughput. vLLM became a strong contender for LLM inferencing through innovative solutions to this fundamental problem.
Four Clever Ideas That Make vLLM Fast
1. Treating GPU Memory Like an Operating System with PagedAttention
PagedAttention is vLLM's star feature—a direct application of Virtual Memory and Paging from classic operating systems to GPU memory management.
Traditionally, each request an LLM serves creates a "key-value" (KV) cache that requires a large, contiguous block of memory. As requests of different sizes come and go, this approach leads to severe memory fragmentation and waste.
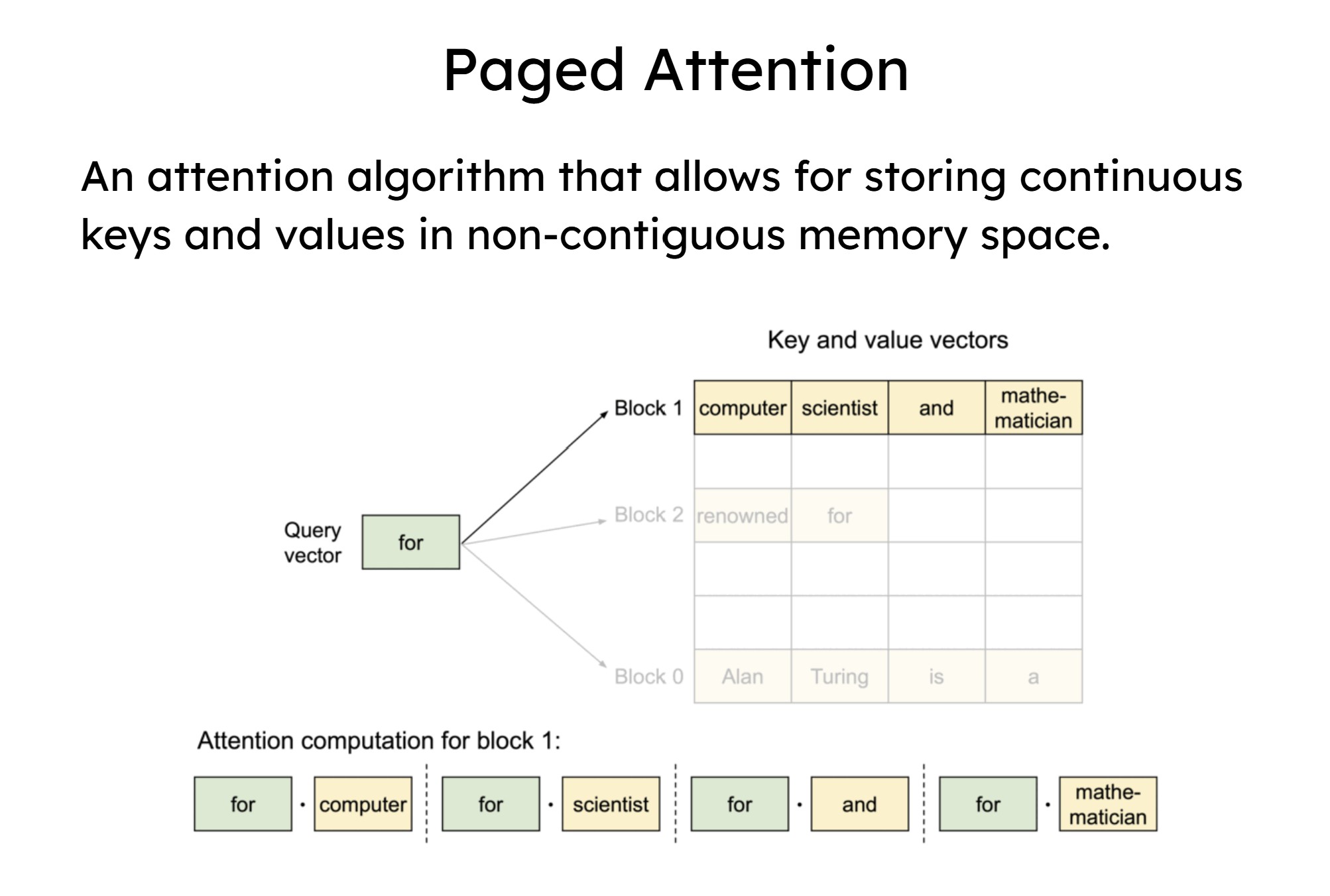
PagedAttention allows storing continuous keys and values in non-contiguous memory space
PagedAttention solves this by breaking the KV cache into smaller, fixed-size blocks, or "pages." Crucially, these blocks don't need to be next to each other in the GPU's physical memory. Instead, vLLM creates an illusion of continuous memory for the model, while managing the scattered physical blocks behind the scenes.
Key benefits:
- Eliminates memory fragmentation
- Allows requests to be packed far more densely
- Dramatically improves GPU utilization and throughput
- Physical blocks are typically 16 or 32 tokens wide to optimize between fragmentation and memory management overhead
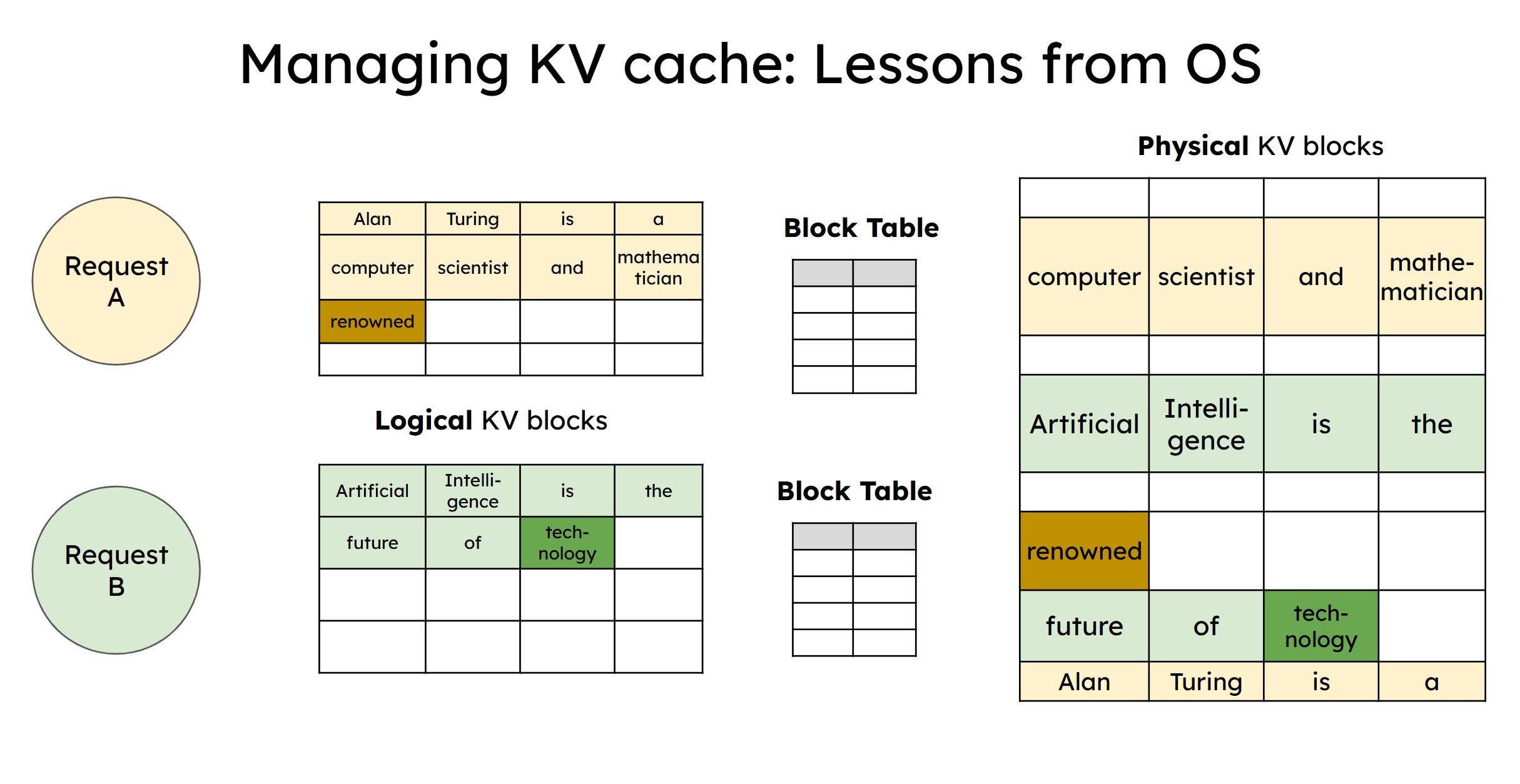
Managing KV cache with logical and physical blocks using lessons from operating systems
2. Fair Traffic Management with Preemptive Scheduling
The scheduler is the "brains of the system" in vLLM, implementing core concepts from process management: Preemptive Scheduling and Starvation Avoidance.
Requests always start in the waiting queue. When picked up, they move to the running queue where model execution begins. The scheduler's most interesting feature is preemption:
If a very large request is taking too long, the scheduler can pause it, move it back to the waiting queue, and give other, smaller requests a chance to run.
This ensures that no single request can monopolize the system's resources. While the default configuration uses First Come, First Served (FCFS), vLLM allows for policy settings to define request priority, enabling the processing of high-priority requests first.
3. Workload Specialization: Splitting Compute-Heavy vs. Memory-Heavy Operations
A fundamental design choice in vLLM is the separation of LLM operations into two distinct phases:
The Prefill Phase: This is the first pass where the system processes the user's initial prompt. This phase is compute-heavy because it involves calculating the key and value vectors for all the input tokens at once, an operation that can be heavily parallelized.
The Decode Phase: This is the step-by-step process of generating the output, one token at a time. This phase is memory-heavy because generating each new token requires the model to access the entire KV cache of all the tokens that came before it.
This separation enables Disaggregated Prefill/Decode (PD)—organizations can build more cost-effective and efficient clusters by using cheaper, compute-focused instances for the prefill phase, while reserving expensive, memory-rich GPU instances only where they are needed for the decode phase.
4. Guided Decoding: Forcing LLMs to Follow Rules
While LLMs are celebrated for their creativity, vLLM provides a powerful feature to enforce strict, predictable structures by applying principles of Formal Grammars and Parsers from compiler design.
How Guided Decoding works:
- A user provides a set of rules (the grammar)
- vLLM converts these rules into a "grammar bit mask"
- After the model calculates the probabilities (logits) for every possible next token, this mask is applied
- The mask sets the probability of any "illegal" token to negative infinity
- When the final probability distribution is calculated, only the "legal" tokens have a chance of being selected
This transforms a non-deterministic, probabilistic system (the LLM) into a deterministic component, making it a reliable tool for structured data extraction and generation in formats like JSON, CSV, XML, or any context-free grammar.
System Architecture Overview
vLLM functions as a distributed inference engine. User requests, whether via an API server, offline inference, or the vLLM CLI, are all unified as requests that enter the LLM Engine.
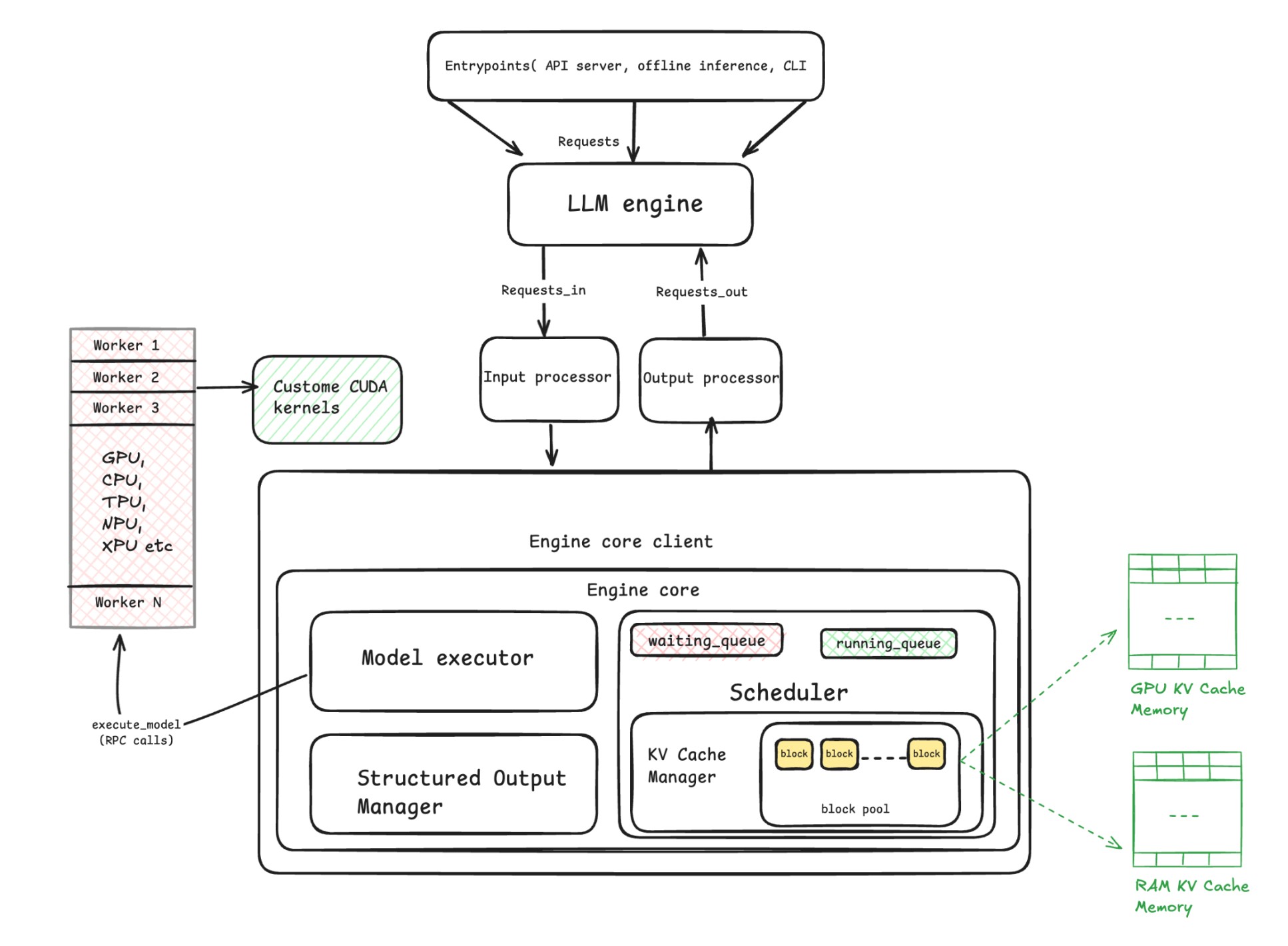
Complete vLLM system architecture showing the flow from entry points to workers
Request Flow and Processing
Input Processing: The request input is tokenized (which also happens for multimodal models), validated, and sampling parameters are generated.
Engine Core: The processed request enters the Engine Core Client, which deals with client-facing operations. The Engine Core is the central component, encompassing the Scheduler, Model Executor, and Structured Output Manager.
KV Cache Management
The KV Cache Manager (KVCM) handles prefill operations and allocates tokens into blocks. It manages a block pool—a collection of virtual blocks, structured as a doubly linked list, which follows the Least Recently Used (LRU) mechanism.
When a request needs blocks, the KVCM assigns free blocks from this pool and provides a block table and mapping. While vLLM primarily targets GPU cache memory, it can use RAM KV cache memory if inferencing is running entirely on CPU.
Model Execution
Model Executor: This component acts as a placeholder in the core engine, transferring the workload to the workers via RPC message passing.
Workers: vLLM supports various workers (GPU, CPU, TPU, NPU, XPUs). They implement a unified interface with a Model Runner. The Model Runner executes the inference cycle, which involves:
- Pre-processing and validating inputs from the scheduler
- Padding tensors for optimized execution via CUDA graphs
- Calling custom CUDA kernels built by vLLM for attention mechanisms (like page attention and flash attention)
- Using RPC calls to contact the KV Cache Manager to read from or write back to memory
Output Processing: Generated tokens flow back through the system to the Output Processor, which detokenizes the output into a legible response before serving it to the client.
Advanced Features
| Feature | Description | Mechanism/Benefit |
|---|---|---|
| Chunk Prefill | A technique for handling very long prompts. | Breaks the prefill operation into multiple, smaller chunks that can be processed in parallel, speeding up the initialization phase. |
| Prefix Caching | An optimization for requests sharing a common, long prefix. | By calculating a hash for blocks containing the common prefix, vLLM avoids recalculating and duplicating Key/Value vectors, saving memory. |
| Guided Decoding | Allows control over the generated output pattern. | Enables generation of structured outputs like JSON, CSV, XML, or any context-free grammar by applying a grammar bit mask to generated logits. |
| Disaggregated PD | Separates the two main operation types (Prefill and Decode). | Allows prefill requests to be routed to compute-optimized instances and decode tasks to memory-optimized instances. |
| Speculative Decoding | Uses a smaller draft model to predict multiple tokens. | Improves throughput by verifying multiple predicted tokens in parallel with the main model. |

Prefix caching avoids recomputing tokens that multiple prompts share at the beginning
Comparative Advantages
Compared to other engines like TensorRT-LLM, vLLM's main strength is PagedAttention and its resulting memory efficiency. vLLM combines this with features like continuous batching, chunk prefill, and priority-based scheduling, making it suitable for industry serving.
Current Challenges and Future Direction
Multimodal Models: These introduce challenges related to the complexity of the process, potentially increasing latency, and affecting placeholder token management. The token budget may also expire sooner.
Future Focus: The next major challenge vLLM is addressing is making hardware plugins more robust to simplify the onboarding of new hardware configurations or specific types of models (e.g., reasoning models).
Conclusion
The high performance of vLLM isn't the result of a single silver bullet. It's the product of thoughtful systems engineering principles applied to the unique challenges of LLM inference. By using virtual memory for the KV cache, preemptive scheduling for fairness, workload specialization for resource optimization, and formal grammars for reliable outputs, vLLM demonstrates how foundational computer science provides the blueprint for making AI practical.
vLLM masterfully reapplies principles from operating systems and compilers to solve modern AI infrastructure challenges. As we continue to push the boundaries of AI deployment, understanding these foundational concepts becomes crucial for building efficient, scalable systems.