Introduction: Beyond the Training Loop
In the world of AI development, we often think in a simple, two-stroke cycle: training and inference. A model is trained on a massive dataset, and then it's deployed to perform inference on new, unseen data. This mental model works for many applications, but it begins to break down when we enter the complex, high-stakes domain of large-scale Reinforcement Learning (RL).
Moving RL systems into production, where an AI agent must continuously interact with live environments, switch contexts, and learn on the fly, reveals a host of non-obvious challenges and performance bottlenecks. These aren't just minor slowdowns; they are fundamental systems-level problems that can cripple throughput and derail training entirely.
This talk distills several surprising and counter-intuitive lessons learned from the trenches of optimizing these massive systems. We'll explore the hidden truths about what it really takes to make production-scale RL not just work, but work efficiently.
1. The Tyranny of the "Long Tail": How a Few Slow Requests Cripple Everything
In many advanced RL tasks, an AI agent engages in "multi-turn I/O," where it interacts with an external tool or API multiple times to complete a single request. Imagine an agent tasked with answering a complex question. It might first call the Google Search API, then parse the results, then call a Wikipedia API to get more detail, generating a response piece by piece.
While this makes the agent more powerful, it introduces a devastating performance problem known as the "long-tail effect." When running hundreds of these multi-step requests in parallel, a few stragglers can hold up the entire system. The performance statistics from production workloads are shocking:
- 80% of requests are completed in the first 50% of the time
- The final, slowest 20% of requests consume the other 50% of the time
- Over 50% of the total time can be spent with most GPU workers completely idle, simply waiting for the single slowest worker to finish
This catastrophic idle time is exacerbated by a common system architecture based on the Single Program, Multiple Data (SPMD) principle without a central router. In this model, the workload is pre-scattered statically across all workers. A worker that finishes its assigned batch early cannot pick up new tasks from slower workers. It is forced to sit idle, creating a scenario where the entire system's throughput is dictated not by the average case, but by the absolute worst case.
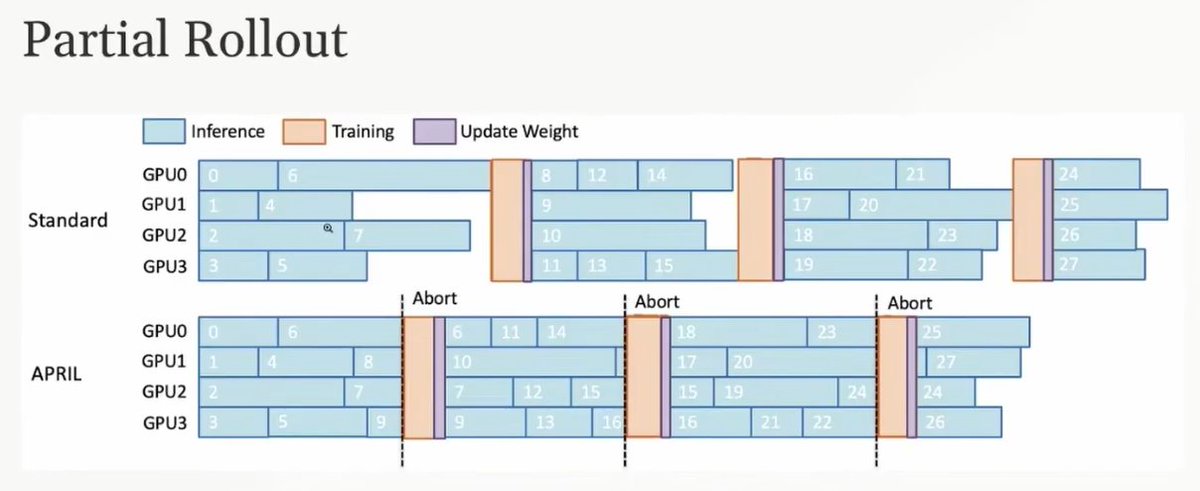
Partial rollout strategy: caching incomplete requests to mitigate the long-tail effect
2. The Unconventional Fix: To Go Faster, Just Throw Work Away
Given the crippling impact of the long tail, the solution is surprisingly unconventional: to maintain high throughput, you sometimes have to throw work away. This strategy is called "oversampling."
The concept is simple. Instead of sending 100 requests to your workers and waiting for all 100 to finish, you send 120. As soon as the first 100 are completed, you simply move on. The 20 slow, unfinished requests are either discarded or postponed. This ensures that the system is never held hostage by the slowest outliers.
Partial Rolling Out: A more sophisticated variant where unfinished requests aren't discarded forever. Instead, they are cached in a data buffer. In the next round of processing, the system prioritizes finishing these cached requests before starting new ones.
This approach balances the need for speed with the goal of eventually completing all tasks. As Zhao notes, this is a pragmatic trade-off required in production environments:
"You may wonder this may hurt the performance on longtail requests but in our internal experiments on production level IO we found that it is a worth trying tradeoff compared with the speed game... honestly speaking to mitigate the longtail effects there's no free launch."
This strategy is not an isolated trick but an emerging best practice. A similar concept, termed "role packer" by a team at Alibaba, also caches the prompts of long-tailed requests to be processed later in a dedicated batch. This reinforces a key reality of production AI: perfect efficiency is often the enemy of practical throughput.
3. The Two-Faced Model: Why Training and Inference Disagree
Here is a deeply counter-intuitive problem: you can have the exact same model, with the same parameters, and give it the exact same input sentence, yet get two different results. This is the "training-inference mismatch," where the highly optimized inference engine (like SGLang) and the training engine (like Megatron) produce different log probabilities for the same output.
The root cause lies in a combination of factors:
- Non-associative floating-point arithmetic: At the scale of large neural networks, the fundamental mathematical rule that (a + b) + c equals a + (b + c) breaks down for floating-point numbers
- Different GPU kernels: The inference and training engines use different underlying GPU kernels, which perform the same calculations in slightly different ways
These tiny differences in calculation order and kernel precision accumulate into a significant final discrepancy.
Critical Impact: This isn't a minor bug; it's a critical flaw that can lead to "training collapse." The RL training process relies on these log probabilities to calculate rewards and update the model. If the model is being trained based on probability values that don't match what it actually produces during inference, the entire learning process can become unstable and diverge.
An initial system-level attempt to fix this was "deterministic RL," which enforces batch-level reproducibility. This is useful for debugging a training collapse but doesn't solve the core mismatch between the two engines. The true solution is moving beyond system-level patches and towards algorithmic ones, such as using Importance Sampling to mathematically correct for the distributional shift between the two systems' outputs during the training calculation itself.
4. The Memory Ghost: Preserving Performance by Pausing the GPU
To save on expensive hardware, it's common to use "collocated placement"—running both the training and inference engines on the same set of GPUs. The system performs inference for a while, then pauses it to run a training step, then switches back. The problem is that this context switch is incredibly slow.
A major source of this slowdown is the need to constantly rebuild the "CUDA graph." A CUDA graph is a low-level optimization where the GPU remembers the entire flow of data and operations for a task. This allows it to execute future runs with minimal interaction with the CPU, providing a massive speedup. However, when you stop the inference engine to run training, this carefully constructed graph is typically destroyed.
CUDA Graph Aware Refit
The solution is a clever trick that hinges on a subtle technical detail: the CUDA graph is tied to virtual memory addresses, not physical memory. A "torch memory saver" tool was created to effectively "pause" the inference engine's memory. This action releases all physical GPU memory for the training job to use while crucially keeping the virtual memory addresses intact.
Once training is done, the system can "resume" the memory, instantly restoring the inference engine with its CUDA graph perfectly preserved.
Multi-Stage Memory Wakeup: A more advanced approach to overcome the limitation where the KV cache cannot expand into freed memory regions:
- Only the serving model is resumed
- New weights from the training run are copied over
- The training engine's memory is fully released
- The KV cache is resumed, allowing it to expand and utilize 100% of available GPU memory
This turns a slow, destructive context switch into a fast, highly efficient pause-and-resume operation, significantly reducing model weight synchronization time.
Key Optimization Techniques Summary
| Technique | Problem Addressed | Solution Approach |
|---|---|---|
| Partial Rollout | Long-tail effect causing GPU idle time | Oversample requests and cache incomplete ones for later processing |
| Importance Sampling | Training-inference mismatch | Mathematically correct for distributional shift between engines |
| CUDA Graph Aware Refit | Slow context switching between training/inference | Preserve virtual memory addresses to maintain CUDA graphs |
| Multi-Stage Memory Wakeup | Limited KV cache expansion after training | Sequential resume process to maximize GPU memory utilization |
Conclusion: The Hidden World of AI Systems Engineering
Scaling AI is not just about bigger models, more GPUs, and larger datasets. As these systems move from the lab to production, their success hinges on solving a series of deep, complex, and often counter-intuitive systems engineering problems.
From discarding work to increase speed, to correcting for the mathematical quirks of floating-point numbers, the challenges are as fascinating as they are difficult. The solutions require a unique blend of algorithmic insight and low-level hardware knowledge.
As AI systems become more integrated with real-world tools and user interactions, what other unexpected bottlenecks are waiting to be discovered? The journey of optimizing production-scale RL systems continues to reveal that the path to efficient AI is paved with pragmatic trade-offs and clever engineering solutions.