We recently had the pleasure of hosting Philip Kiely, an early employee (number 10) at Baseten—an AI inference company based in San Francisco that has grown into a $2 billion company—to discuss the critical topic of embedding model inference. While often overlooked, the performance of embedding models, particularly the intricacies of their inputs and client-side code, significantly impacts how well these systems function in real-world scenarios.
Kiely provided an in-depth look at how Baseten addresses the unique challenges of deploying high-performance embedding services.
Embeddings: More Than Just RAG
Although embedding models are famous for their use in RAG (Retrieval-Augmented Generation) pipelines, their utility extends far beyond this domain. Embeddings are essential components in compound systems, enabling advanced functionalities like context and memory for agents, building entirely new search engines (companies like Exa), sophisticated classification, and high-quality recommendation systems.
Today's deployments rely on two main embedding model architectures:
- Bert Models: These are older, encoder-only neural networks that take text and create vectors. They are still used for very fast, low-latency workloads, such as simple classification tasks, as seen in Superhuman's email app.
- LLM-Based Models: These models are derived from powerful open-source large language models (LLMs) like Llama or Mistral, built by startups like Nomix. They are significantly larger, often having about 10 times as many parameters as previous generations. They handle various input modalities, including strings of different lengths and images, and benefit from the same high-end inference optimizations developed for LLMs, utilizing architectures like Hopper and Blackwell.

Comparison of Bert/Encoder-only vs. LLM-based models and their typical use cases.
The Unique Two-Part Workload Challenge
The major difficulty in deploying embedding inference services is supporting a unique two-part workload that often pits high throughput against low latency.
Embedding services must simultaneously handle:
- High Throughput Batch Processing: Large batch jobs for tasks like backfilling a corpus, embedding data preprocessing for training, or creating vector databases.
- Low Latency Single Queries: Encoding individual user queries during live inference (e.g., hitting the vector database in a RAG system).
The requirement to support both these extremes at the highest levels of performance is what makes embedding deployment complex. Baseten, for example, successfully helps companies like Superhuman manage both model types and both workload profiles.
The Optimized Pipeline: TensorRT-LLM and Quantization
To tackle these inference challenges, Baseten primarily utilizes an optimized technology stack centered around NVIDIA's TensorRT-LLM (TRT-LLM).
While other engines like VLLM (an open-source LLM inference engine) and TEI (Text Embedding Inference from Hugging Face, which supports both model types) are available, TRT-LLM is favored because it provides highly optimized kernels, inflight batching support, engine compilation capabilities (kernel fusion and selection), and supports modern GPU architectures like Blackwell.
The high-performance pipeline looks like this:
- A model server processes and formats inputs.
- The request goes to a parallelized tokenizer which converts strings into tokens in batches.
- A separate batch manager feeds the tokens into the inference engine, ensuring the tokenizer queue and the inputs queue don't bottleneck each other.
- TensorRT-LLM performs inference using in-flight batching, creating the embedding vector outputs.
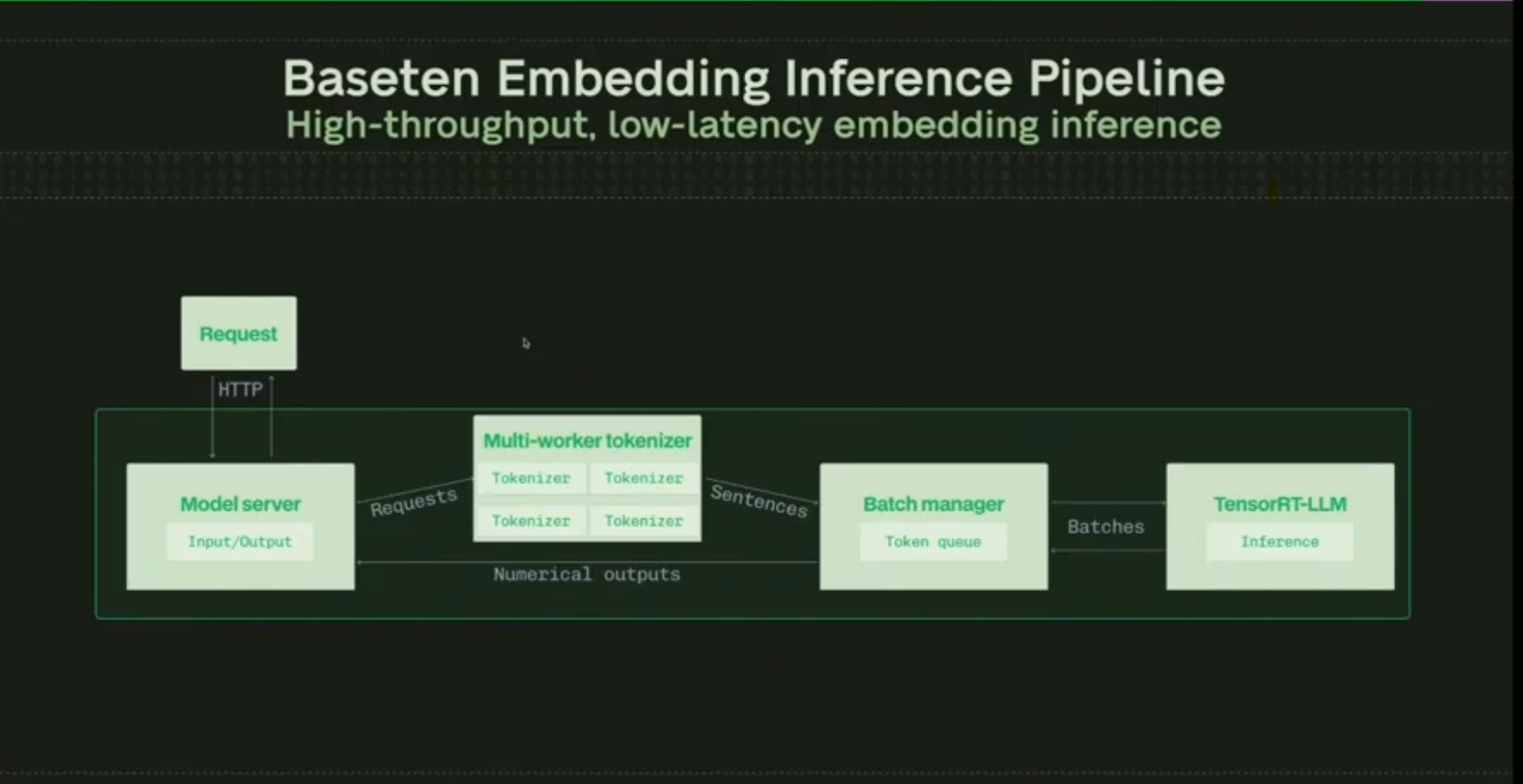
Detailed pipeline showing the flow through server components to prevent bottlenecks.
Precision and Performance Gains
A key optimization technique in this stack is the use of low precision inputs. While FP16 (16-bit floating point) is standard for high quality, Baseten has found that FP8 (8-bit floating point) works very well for LLM-based embedding models. Quality is verified by ensuring the cosine similarity between the FP8 output vector and the original FP16 vector is extremely high (e.g., more than 99.9% similarity).
This quantization delivers substantial speedups: on an H100 GPU, using FP8 can yield 50% more token throughput compared to FP16. When combining TRT-LLM, quantization, and Blackwell support, performance can meaningfully outperform VLLM or TEI setups, sometimes achieving a 3x improvement in token throughput.
For Open Evidence, a major customer utilizing this technology (often described as "chat GPT for doctors"), this optimization stack led to a massive 78% reduction in latencies, bringing query times down from over 700 milliseconds to just 160 milliseconds.
How to Balance Latency and Throughput
A central question in high-performance inference is how to balance maximizing batch throughput for large jobs with minimizing latency for real-time applications.
Kiely explained that this balance is achieved primarily through the combination of the batch manager and in-flight batching in TRT-LLM. The system is inherently designed for latency first:
- In-flight batching allows the system to accept individual requests and kick them off immediately as tokens become available.
- High-end GPUs (H100/B200) offer vast amounts of VRAM (80 GB to 180 GB). Since many embedding models are small (7 or 8 billion parameters), there is significant headroom for large batch sizes and substantial KB cache.
This available headroom allows the latency-optimized system to effectively be saturated for high-throughput batch workloads when needed.
Beyond the Server: Client-Side Optimization
Optimization must extend beyond the inference engine itself to achieve true end-to-end performance.
For extremely high-throughput deployments, the bottleneck is often the client code. To address this, Baseten developed the baseline performance client, an open-source, Rust-based tool that replaces standard SDKs (like the OpenAI SDK). This client allows users to bypass the Global Interpreter Lock in Python, enabling parallel request sending and generating up to 12 times as much throughput in high-traffic scenarios.
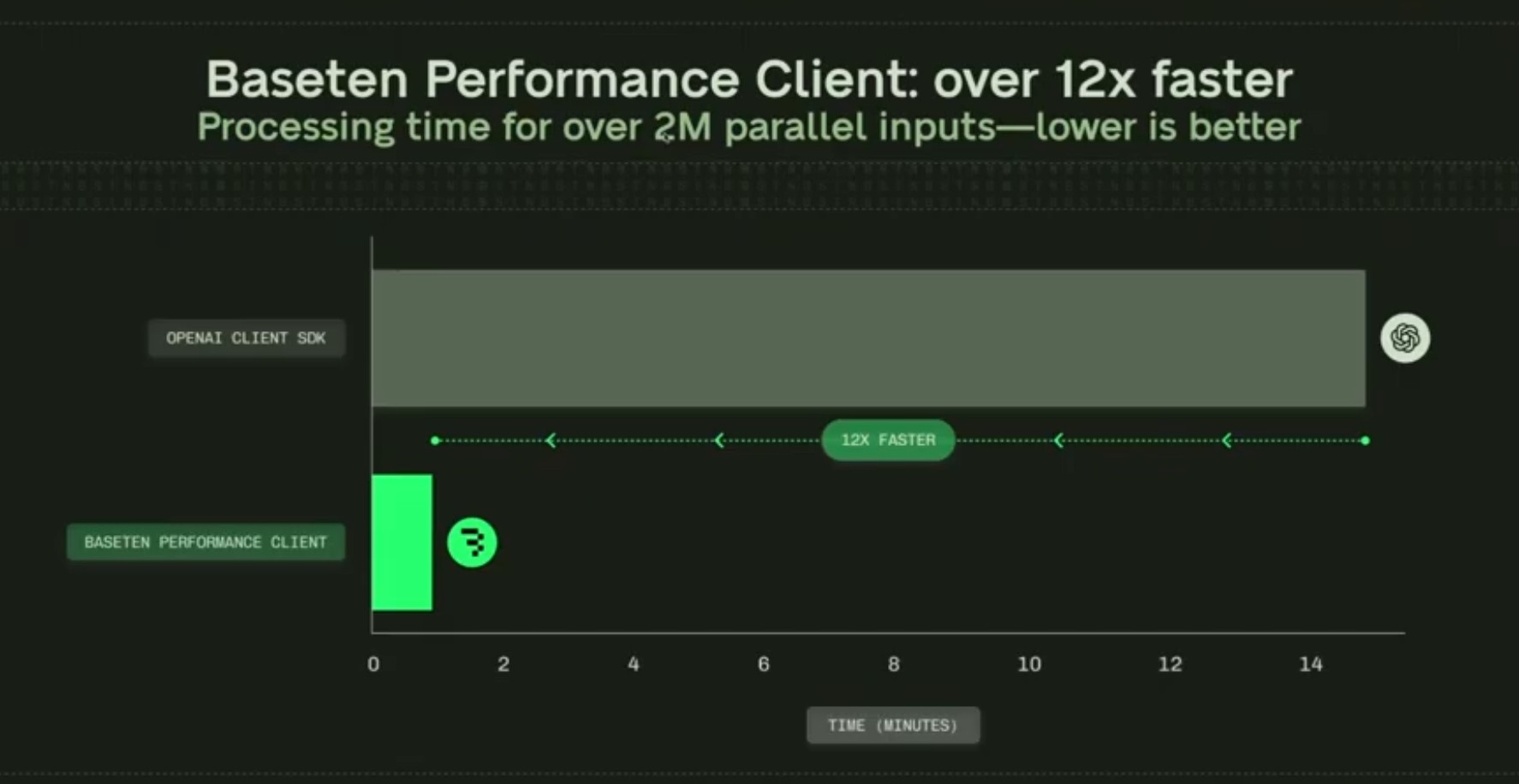
Throughput performance comparison between Standard OpenAI Client SDK and Baseten/Rust-based performance client.
Additionally, infrastructure decisions, such as using granular and independent autoscaling based on traffic (not just utilization), are critical to avoid tail latency effects, especially when dealing with complex, multi-stage pipelines where embedding models and LLMs may require different resources. Companies like Latent Health, focusing on question answering, used this comprehensive approach to push P90 latency below 600 milliseconds while substantially improving GPU utilization.
Conclusion
In summary, achieving high-performance embeddings requires a full-stack approach: the right open-source models, an optimized runtime (like TensorRT-LLM), and robust infrastructure and client-side code.
If you are interested in deep-diving into model performance engineering, Philip Kiely noted that Baseten is constantly hiring, especially for roles focused on kernel work and contributions to inference engines. You can find more resources and detailed blog posts on the Baseten blog.