We recently had the pleasure of hosting William Arnold from the NVIDIA Dynamo team, who shared an in-depth look at Dynamo, a platform designed for really high performance open source inference. Dynamo is publicly available on GitHub, boasts comprehensive documentation, and welcomes contributions from the open-source community.
The creation of Dynamo was driven by the challenging requirements of scaling up modern Language Model (LLM) serving, particularly utilizing a technique known as disaggregated serving.
The Necessity of Disaggregated Serving
When working with a chatbot, the process generally splits into two computationally distinct stages:
- Prefill: Processing the initial question (the prompt). This stage is compute bound, requiring a high amount of processing and computation.
- Decode: Spitting out tokens one by one (the response). This stage is memory bound, requiring constant reading of large amounts of data from memory.
Because these stages have different computational limits, splitting them—often across different GPUs—allows for better hardware utilization and maximized inference performance. While disagregation can offer performance improvements even on a single GPU, the benefits become significantly pronounced when using two or more GPUs.
For example, benchmarks show that at a specific throughput, utilizing disaggregation can yield twice the performance compared to a non-disaggregated baseline.
The Challenge of Massive Scale
Dynamo is built to handle infrastructure at a massive scale, capable of supporting huge amounts of compute. Consider a scenario involving four racks containing 288 GPUs, configured to hold 24 model replicas. Such a system can handle 64,000 in-flight requests concurrently, processing 1.9 thousand requests per second (about 30 seconds per request). Crucially, this setup delivers 1.4 million output tokens per second, where each token streamed creates a new entry in the KV cache—the system’s memory.
Beyond raw throughput, a successful serving system must address major system-level challenges:
- Fault Tolerance: Any piece of hardware can fail at any moment (e.g., a GPU going offline, or a network issue). The system must be prepared to continue serving requests seamlessly.
- Dynamic Load Balancing: The load changes throughout the day, requiring the ability to scale up or scale down GPU usage to handle peak times or utilize resources for other workloads.
Achieving success isn’t just about having a good model; it requires a robust system like Dynamo that can handle thousands of users and these high-stakes problems.
Dynamo’s Component Architecture
Dynamo addresses these challenges through a collection of integrated components.
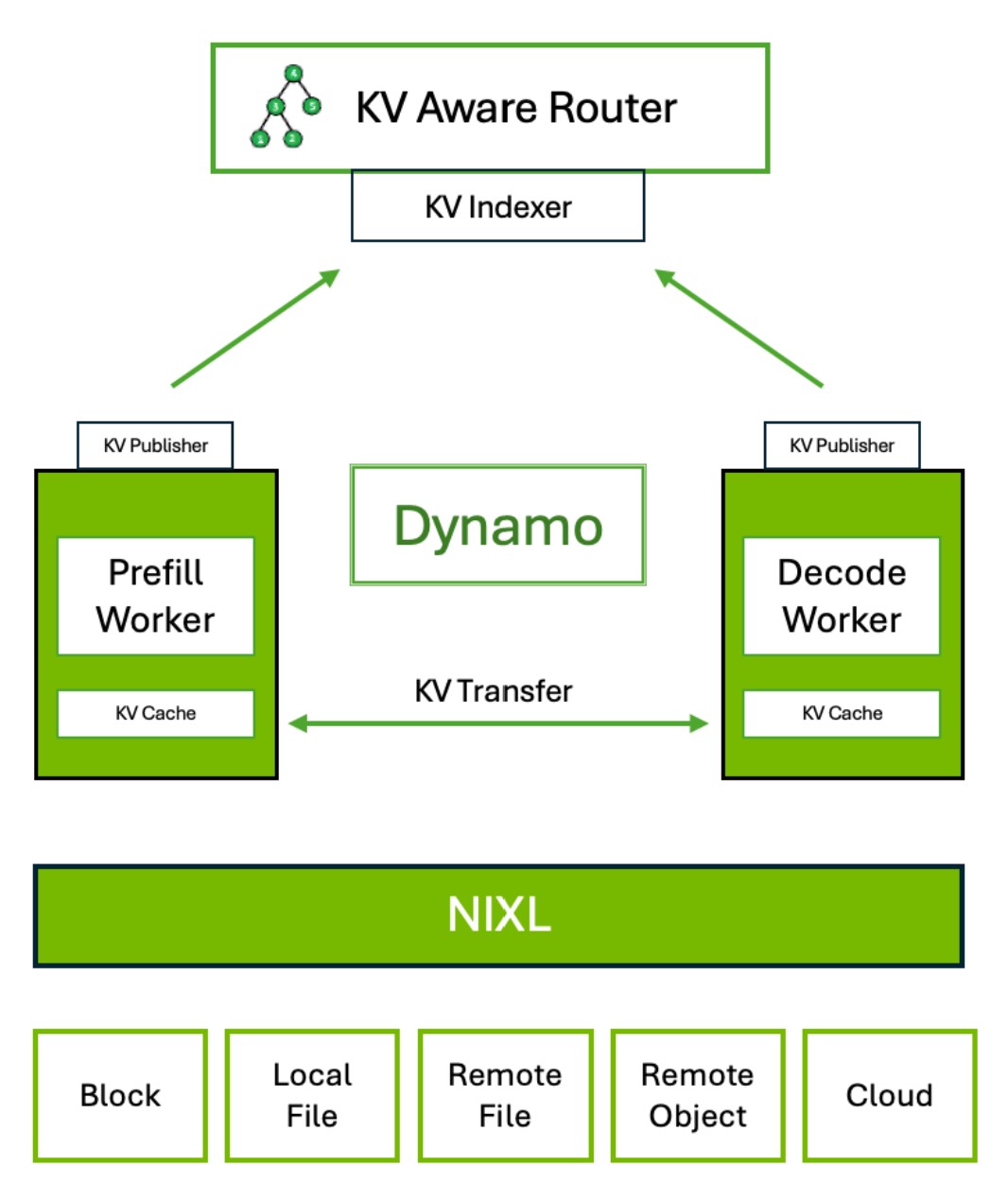
KV Aware Router Diagram
1. The Worker Registry (Health & Discovery)
The simplest component, the Worker Registry, relies on a tool like Etcd. Its job is straightforward: know which servers are online, and if they go offline, notify everyone. Prefill and decode workers register themselves and maintain communication links. If a node fails, the registry immediately notifies the rest of the system, including the HTTP front end.
2. The HTTP Front End (Fault Tolerance Maestro)
The Front End handles incoming requests. A request first goes through a pre-processor (a CPU-intensive task) for tokenization. It then hits the Migration Handler, which works with the Router to select a worker.
The Migration Handler attaches information about the chosen worker and route to the request. If a worker dies mid-request, the Worker Registry notifies the Front End. Because the Front End has kept track of the request's full state (input and partial output), it can immediately migrate the request by finding a new node and restarting processing. This provides crucial node-level fault tolerance, ensuring users don’t just see an error if a backend node fails.
3. Workers and Asynchronous Transfer
Dynamo is designed to be engine-agnostic and easy to integrate with existing serving engines like TensorRT-LLM, vLLM, or SGLang. Workers register with the Worker Registry.
A key mechanism is the asynchronous transfer of the KV cache. When a request comes in:
- Decode allocates KV cache space.
- Prefill computes the KV cache.
- Prefill asynchronously copies the KV cache to the decode worker.
- Decode is only notified once the copy finishes, allowing it to continue processing other requests in the meantime.
4. The Router (The Intelligence Hub)
The Router is one of the stars of Dynamo. Its primary function is to handle requests reusing previous KV caches, especially important in multi-turn conversations where the chatbot reuses context.
The Router maintains a global view of the entire system by building a Radix Tree. This structure maps every prefix of a conversation to which worker holds the KV cache for that prefix. When routing a new request, the Router scores potential workers based on two factors:
- KV Cache Overlap: How much of the existing prompt matches cached KVs on that GPU.
- Worker Load: How full the GPU memory is and how many requests it is currently processing.
This sophisticated routing decision ensures the request goes to the most optimal location, maximizing cache reuse and minimizing latency.
Router Fault Tolerance via Persistent Stream
Because routers can die, all routing decisions, token processing, and state updates (including cache evictions) are written to a persistent stream (Dynamo uses a tool like a Max Jet Stream). This stream provides an eventually consistent log of all events. If a router dies, a new one can be spun up, read the entire log from the persistent stream, repopulate its internal data structure (the Radix Tree), and immediately continue serving.
5. KV Block Manager (KVBM) (Offloading Storage)
GPU memory (HBM) is expensive and limited. The KV Block Manager (KVBM) manages memory pressure by implementing sophisticated offloading. Instead of discarding evicted KV caches, KVBM can move them from GPU memory down to:
- Host (CPU) memory.
- Disk.
- External storage.
This is vital for long context windows (like 20k context or multi-turn agentic conversations) where the KV cache fills up rapidly. By efficiently caching KVs even off-GPU, Dynamo yields substantial performance improvements—benchmarks have shown 57% to 68% reductions in time to first token just from enabling this caching utility.
6. Planner (Resource Optimization)
The newest component, the Planner, is designed to optimize resource allocation over time. It ingests data about deployment load, input/output sequence lengths, and model profiling.
Given constraints (like user SLA targets), the Planner computes a schedule for how many prefill workers versus decode workers should be spun up or down at any given time. For example, during peak coding hours requiring large context prefilling, it might spin up more prefill workers.
Planner leverages load predictors (like ARMA or Prophet) and uses the open-source Dynamo library Grove for network-aware scheduling on Kubernetes. Alibaba, for instance, reported that using Planner allowed them to achieve five times better performance while using 5% fewer GPUs.
Proven Impact
Dynamo’s focus on clever system-level optimizations, rather than intricate core GPU optimizations, leads to huge performance gains.
Base Ten, a large inference provider, documented their use of Dynamo and found that turning on the KV router halved the average time to first request and resulted in close to a 50% improvement in time per output token. This improvement was seen across all latencies (P50, P95, P99), reducing the time taken even by the longest requests.
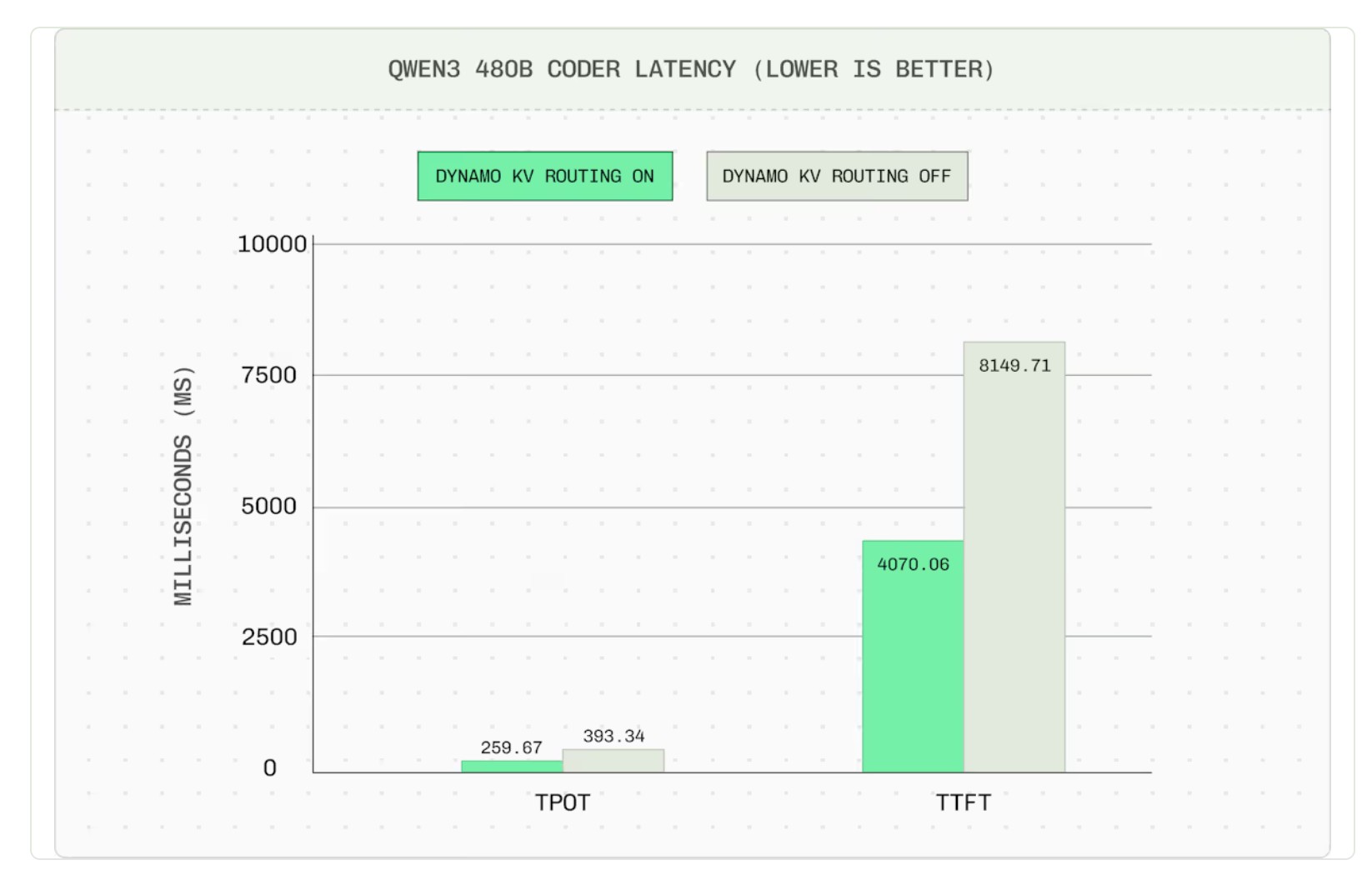
Description: KV routing results in a 34% reduction in TPOT and 50% reduction in TTFT on average with an 89% hit rate across four replicas. [Image Source]
Looking Ahead
The rapid advancement of hardware demands that software stays ahead of the curve. NVIDIA’s Hopper generation saw a 4x improvement in throughput over previous generations. The upcoming Ruben generation includes the Ruben CPX chip, specifically built for prefill and optimized for disaggregated serving, utilizing GDDR6 memory (lower bandwidth, less expensive) for compute-bound tasks.
The Dynamo team is dedicated to ensuring that its system-level features can scale and support these future generations, delivering massive performance gains for its users. Dynamo’s goal is to be the easiest way to implement disaggregated serving, supporting everything from small two-GPU setups up to massive racks.