Overview
When we think of Artificial Intelligence, the image that often comes to mind is one of massive, centralized cloud data centers processing unimaginable amounts of data. But a new frontier is rapidly emerging where AI is leaving the cloud and moving to the "edge"—processing data directly on local devices, from factory floors and retail stores to remote telecom towers where low latency is a critical business driver.
However, moving AI to the edge isn't as simple as just shrinking cloud solutions to fit on smaller hardware. This talk explores the surprising technical realities and counter-intuitive challenges of building intelligent systems outside the data center, revealing insights that challenge common assumptions about Edge AI deployment.
The Foundation: Rethinking Operating Systems for the Edge
One of the most fundamental shifts in Edge AI isn't about the models themselves—it's about the operating system layer. The traditional approach of managing servers with package-based OS installations becomes brittle and inconsistent when you're managing thousands of devices across vast distances.
The revolutionary approach gaining traction is the immutable, image-based OS. Instead of managing individual packages over a device's lifetime, this model bundles the entire operating system, drivers, and all necessary software into a single, version-controlled, container-like image—what Red Hat calls a "bootable container."
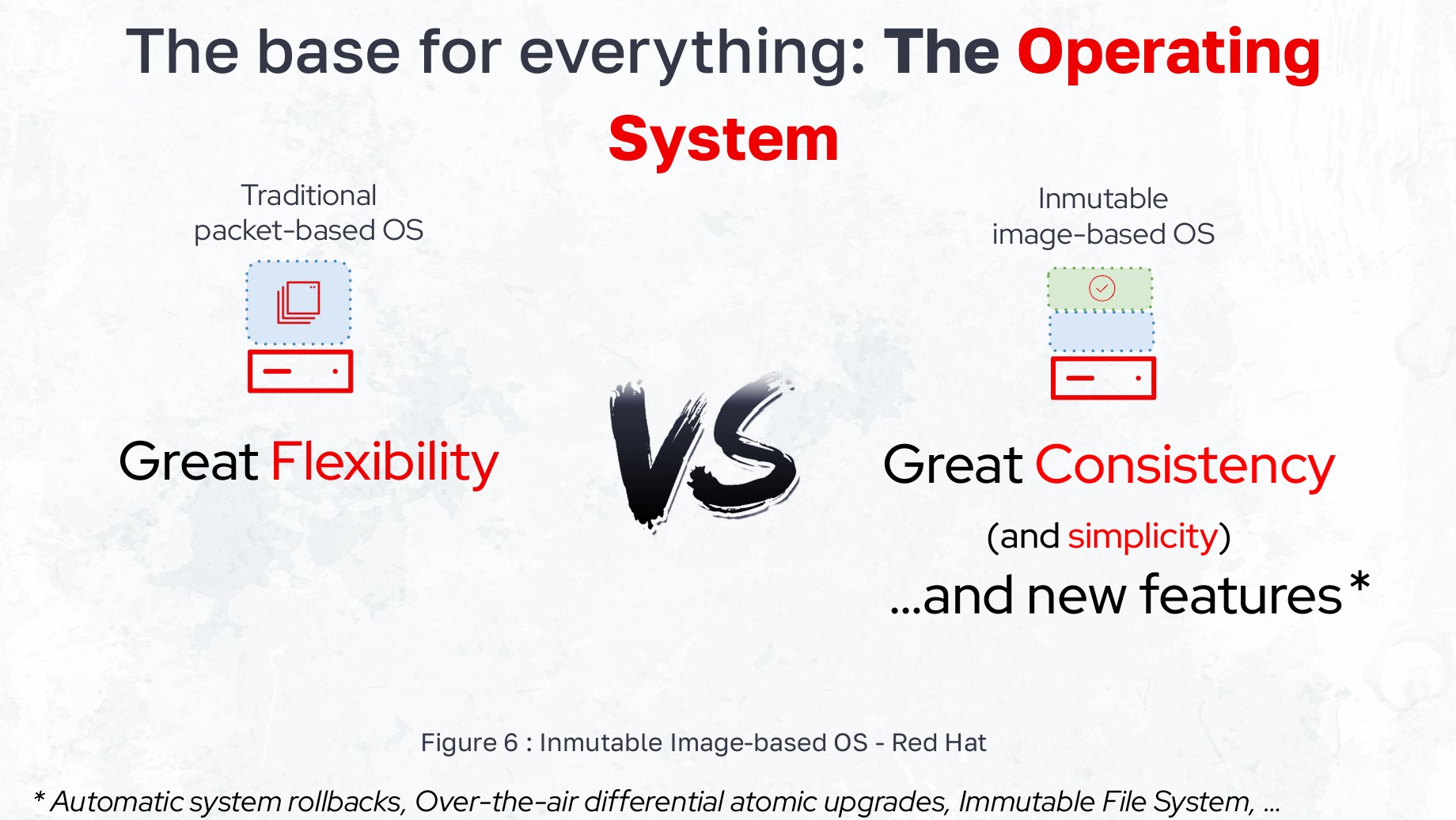
Comparison between traditional packet-based OS and immutable image-based OS deployment strategies
This approach provides several critical advantages for Edge AI:
- Consistency and Simplicity: Every device deployed from the same image is identical, eliminating configuration drift
- Simplified Security: Patching is no longer about managing individual package vulnerabilities—you simply replace the entire old image with a new, patched one
- Speed and Automation: Enables rapid, automated deployments and powerful features like over-the-air (OTA) upgrades and automatic rollbacks if an update fails
For Edge AI, this stable foundation directly impacts time-to-market, allowing companies to deploy and update AI services faster while providing a predictable environment to run models on potentially thousands of distributed devices.
The GPU Challenge: It's Not Plug-and-Play
Given the central role of GPUs in powering modern AI, it's natural to assume that adding one to a container orchestration platform like Kubernetes would be straightforward. This assumption is incorrect, and understanding why reveals critical friction points in modern AI infrastructure.
The core problem is that Kubernetes was not natively designed to manage or schedule workloads for specialized hardware like GPUs. By default, its scheduler only understands and allocates CPU and memory resources. Even when a pod is placed on a GPU node, the container environment is too isolated to interact with the underlying GPU devices.
To bridge this gap, a significant layer of specialized software is required—the NVIDIA Container Toolkit and custom device plugins must be installed on the cluster to make the physical GPU "visible" and accessible to containers. This involves:
- Making GPU device files visible inside the container
- Loading the correct libraries to communicate with the GPU
- Setting up the CUDA context properly
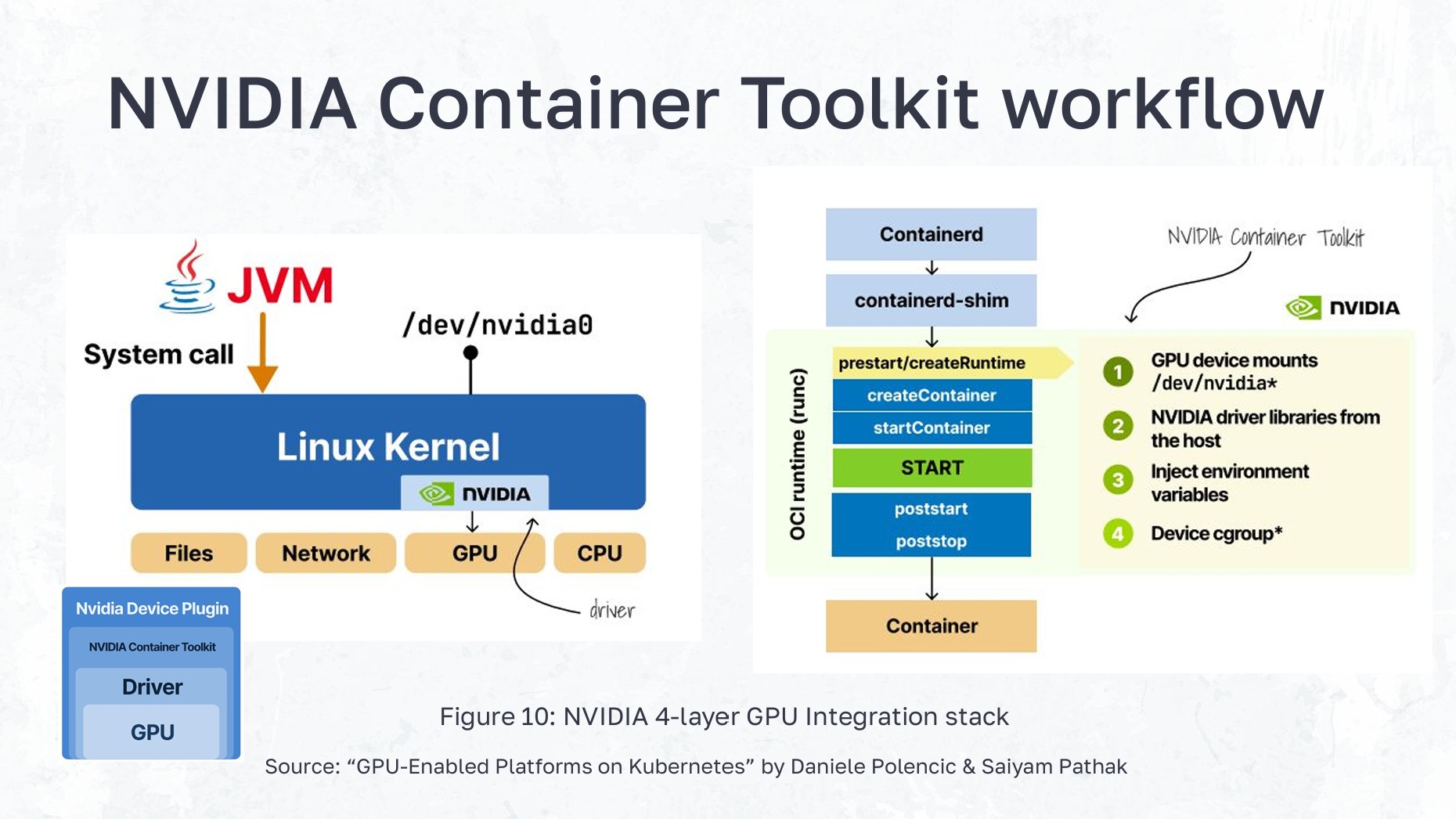
The NVIDIA 4-layer GPU integration stack showing how containers access GPU resources through device plugins and the container toolkit
This reveals an important insight: despite Kubernetes' goal of universal abstraction, deploying AI at the edge still requires deep, specialized integration to make the very hardware that powers AI work effectively.
GPU Sharing: A Game of Strategic Trade-Offs
Once you've solved the challenge of making GPUs visible to Kubernetes, you immediately face a more complex question: how do you share these powerful but expensive resources efficiently among multiple applications, models, or users?
There is no single "best" way to share a GPU—each method involves fundamental trade-offs:
- Multi-Process Service (MPS): Allows multiple processes to run concurrently on the GPU, prioritizing raw performance at the potential cost of isolation and safety
- Time-Slicing: Gives different processes access to the GPU by dividing processing time, offering stronger isolation in exchange for simplicity
- Virtual GPUs (vGPU): Creates virtual machines that each believe they have their own dedicated GPU, offering the strongest isolation but with performance overhead
This forces architects to make fundamental, upfront decisions about their application's core priorities. The right choice depends entirely on whether your application requires maximum speed, strict security, or simple configuration—adding another layer of complexity to Edge AI design.

Different GPU sharing strategies: MPS for concurrent access, time-slicing for balanced approach, and vGPU for maximum isolation
Smarter Beats Bigger: The Edge Optimization Imperative
The prevailing narrative in AI, particularly with Large Language Models, has been that "bigger is better." However, for resource-constrained edge devices with limited power and processing capability, this approach is completely impractical.
The key to success at the edge isn't raw power—it's optimization. The most effective strategy is to tune a smaller, more efficient AI model for a very specific use case. For example, instead of using a massive, general-purpose LLM, create a model designed only to answer questions about a specific domain. By removing all unnecessary knowledge, the model's complexity and resource requirements are drastically reduced.
The most surprising outcome? Effective optimization can completely eliminate the need for expensive, power-hungry GPUs. This signals a potential market shift where value moves from raw hardware providers to the ecosystem of MLOps tools and engineering talent capable of sophisticated model optimization.
Hardware-Software Co-Design: The Path Forward
Successful Edge AI deployment requires more than just deploying smaller models—it demands a holistic approach to hardware-software co-design. This includes:
- Custom Accelerators: Purpose-built hardware like NPUs, TPUs, and specialized ASICs optimized for specific AI workloads
- Hardware-Aware Compilers: Tools like Intel OpenVINO and Google Edge TPU Compiler that optimize models for specific hardware
- Model Architecture: Designing model structures that align with hardware capabilities and constraints
This co-design approach recognizes that Edge AI success comes from the deep integration of hardware, software, and AI models working in symbiotic harmony under significant constraints.
Key Takeaways
The journey of deploying production-ready AI at the edge reveals several critical insights:
- Operating System Innovation: Immutable, image-based operating systems provide the stable, consistent foundation needed for managing AI at scale across distributed edge devices
- Infrastructure Complexity: Kubernetes requires specialized integration to effectively leverage GPUs, and each sharing strategy involves fundamental trade-offs between performance, security, and simplicity
- Optimization Over Scale: At the edge, smaller optimized models can outperform larger general-purpose ones, potentially eliminating the need for expensive GPU hardware
- Specialized Engineering: Success requires deep co-design of hardware, software, and AI models—it's not about scaling down the cloud, but about purpose-built solutions for constrained environments
As AI becomes more decentralized and embedded in the world around us, the most valuable innovations may come not from building the biggest "brains" in the cloud, but from mastering the complex art of making efficient AI work anywhere.